On defining the architecture, we looked for stable and known components. This guideline provides fast developing, stability and focus on implementing the detection algorithms and don’t wasting time with accessories. Also, we tried to create an environment able to process a big amount of data.
In this scenario, the Hogzilla IDS is supported by the following pieces.
- Apache Spark – Used to process the detection routines. These routines are coded in Scala and available in Hogzilla.jar.
- HBase/Hadoop – Keeps the data to be processed and the processed data.
- Snort – Collects network packets, sometime associated with its respective events generated by Snort, and save it in an Unified2 file.
- Barnyard2-hz – Reads the Unified2 file (packets and some events), perform DPI and save flows’ features into HBase.
- lib nDPI – Used to DPI and to identify some known traffic. These information may be used in detection routines.
- GrayLog – An “Open source log management that actually works”.
- Snorby – An alternative monitoring console. We recommend to use GrayLog.
- SFlow2Hz – A simple binary used to insert sFlows into HBase.
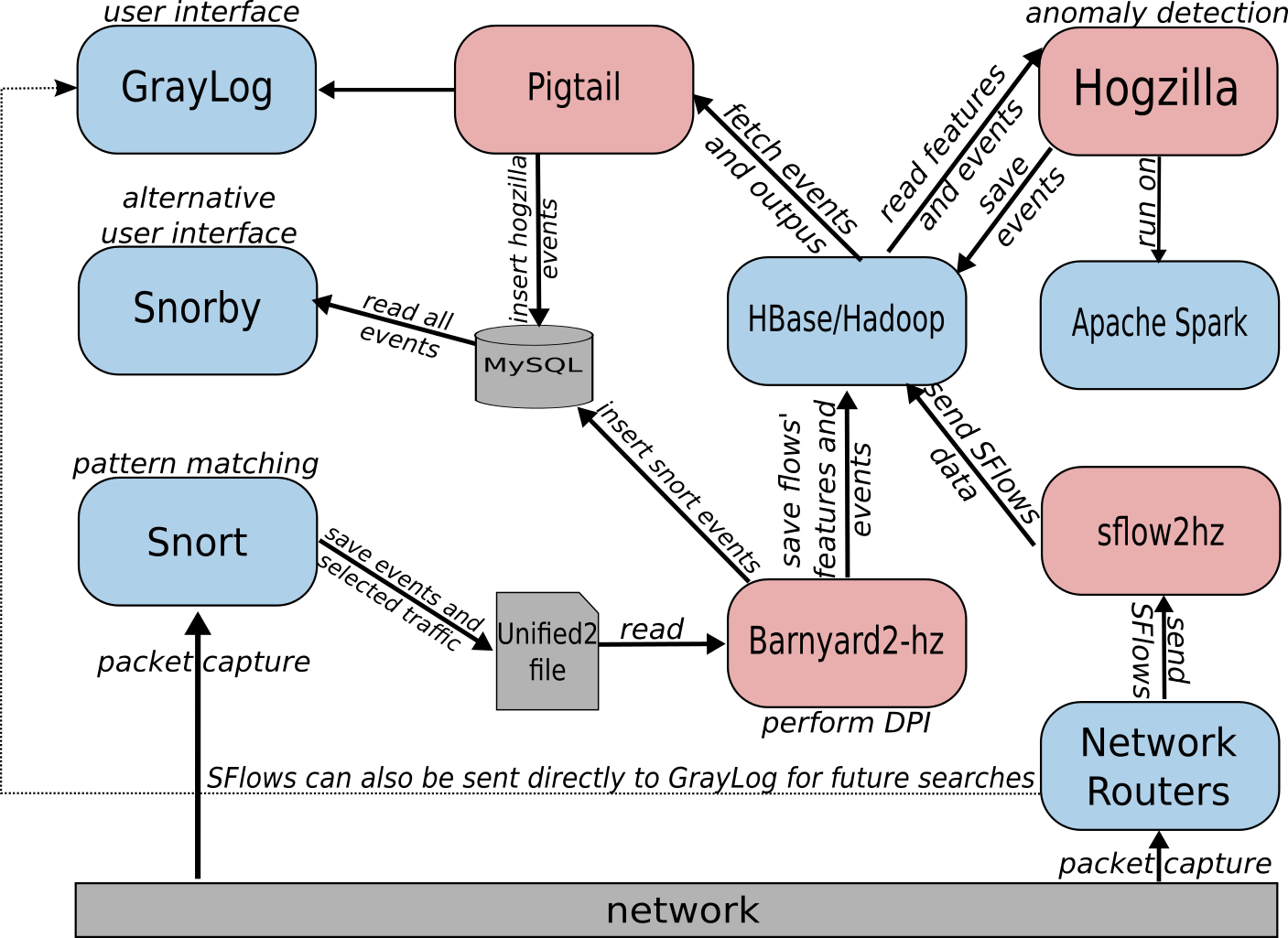
The architecture has low coupling and allows module changes without many troubles. This is useful to keep updated with technologies. For example, it is possible to use flows collected by Snort, sFlows or both.
The features generated by Snort/Barnyard2-hz/nDPI, saved in HBase and processed by the detection routines are listed in the table below.
| Feature |
|---|
| flow:lower_ip |
| flow:upper_ip |
| flow:lower_name |
| flow:upper_name |
| flow:lower_port |
| flow:upper_port |
| flow:protocol |
| flow:vlan_id |
| flow:last_seen |
| flow:bytes |
| flow:packets |
| flow:flow_duration |
| flow:first_seen |
| flow:max_packet_size |
| flow:min_packet_size |
| flow:avg_packet_size |
| flow:packet_size_stddev |
| flow:avg_inter_time |
| flow:inter_time_stddev |
| flow:payload_bytes |
| flow:payload_first_size |
| flow:payload_avg_size |
| flow:payload_min_size |
| flow:payload_max_size |
| flow:packets_without_payload |
| flow:detection_completed |
| flow:detected_protocol |
| flow:host_server_name |
| flow:inter_time-%d |
| flow:packet_size-%d |
| DNS only features |
| flow:dns_num_queries |
| flow:dns_num_answers |
| flow:dns_ret_code |
| flow:dns_bad_packet |
| flow:dns_query_type |
| flow:dns_query_class |
| flow:dns_rsp_type |
| HTTP only features |
| flow:http_method |
| flow:http_url |
| flow:http_content_type |
| If there exists Snort event |
| event:sensor_id |
| event:event_id |
| event:event_second |
| event:event_microsecond |
| event:signature_id |
| event:generator_id |
| event:classification_id |
| event:priority_id |
The first available (v0.5.x-alpha) version has two simple implementations of k-means clustering merely to validate the architecture.
The current version (v0.6.x-beta) supports sFlows and also provides servers clustering and inventory information gathering from sFlows.
For more details, we recommend the Roadmap page.
Hogzilla IDS is also designed for scientists, to be used as a framework for testing approaches. In this way, Apache Spark and the Scala language is suitable.
Preliminary results
The sFlows methods are stable and functional. Also, we found some arrangements that provided good results. We intent to publish it soon in details.
Research guidelines
Presently, we have been guided by some published work. As expected, we always find some troubles implementing routines based on approaches proposed in literature (theory vs practise dilemma).
We strive to test the routines in real networks, with real threats. I believe that testing on KDDCUP99 would not be a good idea.